

Lightly Curation
スイス チューリッヒを拠点にするコンピュータビジョンAI開発向けキュレーションツールのスタートアップ企業Lightlyは、AIモデル開発時のデータセット選択のプラットフォームです。
コンピュータビジョン向けAI開発の課題
データ活用の課題
収集された画像やビデオのデータは大量に社内にあるが、AIモデルの学習用に活用できているのが僅か
データ探索の課題
ビデオデータの中から、エッジケースを探し出して、学習用データセットを作る工数が膨大に
データの偏りの課題
モデル学習用のデータセット自体に偏りがあるため、ある程度までの精度が出るが、それ以上の精度向上が難しい
データパイプラインの課題
データセット選択のプロセスが、モデル学習のプロセスとの自動化ができておらず、しばしば手戻りが発生
コンピュータビジョン向けAI開発では、大量に収集されたビジュアルデータ(写真、ビデオ)から学習用に必要な、データを選択後に、アノテーションの作業が必要となります。
ラベル付けが未だされていないようなデータから、出来る限り冗長なデータを排除し、また外れ値や特殊なエッジケースのシナリオが入っている画像ついては保持する必要が有ります。
残念ながら、多くのコンピュータビジョン分野のAI開発では対象画像数が膨大なために、全ての画像にラベリングを行う事は不可能に近く、ランダムな画像選択手法が主に用いられて来ましたが、数%の精度向上という壁で行き詰まる事例も多くなって来ています。
可能であれば、より少数のラベル付きデータセットでモデルをファインチューニングしたい、何百万ものラベルなしデータサンプルの中から、最適な学習用データセットをサブセットとして選択して、汎化率を向上させバイアスを低減させたいというニーズが高まっています。
このようなニーズに、Lightly社が画期的な解決策を提供します。
AI開発における複雑かつ時間を要する画像・映像データ処理の
キュレーションのフェーズに「自己教師あり学習」と「能動学習」の技術を組み込んだ
キュレーションツールにより、アノテーションの
コストと時間も大幅に節約することを可能にしました。

AI開発における複雑かつ時間を要する画像・映像データ処理のキュレーションのフェーズに「自己教師あり学習」と「能動学習」の技術を組み込んだキュレーションツールにより、アノテーションのコストと時間も大幅に節約することを可能にしました。
ダウンロード資料
Lightly コンピュータビジョンでのデータ問題 5つの解決策
Lightlyが提供する、コンピュータビジョンデータの課題に対する5つの革新的な解決策を、道路画像の公開データセットComma10kを用いて紹介します。
データの理解から始まり、データキュレーション、効率的なデータパイプラインの構築、データ管理、そして社内データ共有に至るまで、機械学習エンジニアが直面する一連の課題を解決する方法を探ります。
どんなにモデルの完成度を高め、性能を向上させても、その成果は学習されたデータの質に左右されるため、このアプローチは非常に重要です。
Lightlyのアプローチは、データセットのポテンシャルを最大限に引き出し、機械学習モデルの精度と効率を飛躍的に向上させることを目指しています。
この解決策は、データ駆動型の未来に向けて、技術の新しい地平を開きます。
(ダウンロード資料:7ページ/5,900文字)
詳しくは、
ダウンロード資料をご確認ください

キューレーション
大量のデータセットから関連性の高いデータを選別し、正確なラベル付けには膨大な作業量が必要です。このプロセスは、開発プロジェクト全体の8割にも及ぶと言われています。
そして、このプロセスには時間が掛かるだけでなく、手作業ではエラーが混入する可能性も高まり、結果としてAIモデルの精度に大きな影響を及ぼすことになりかねません。
既に構築されている開発時のデータパイプライン中に、高品質なデータ抽出を可能とするLightly のデータキュレーションのソリューションをインテグレートすることにより、収集したデータの徹底的な理解とデータ選択のプロセスを最適化させることが可能となります。
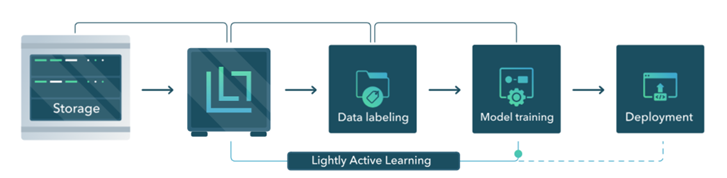
特徴
コンピュータ・ビジョンの開発において、多様なデータは特に重要であり、日々大量に収集が進みます。
しかしながら、収集されたデータは生の状態、すなわち未加工の状態のままあるため、ほとんどがアノテーション作業前の段階で、そのまま活用されていません。
さらに、ラベリングなどの処理ステップは非常にコストと時間がかかるため、データセットの中のごく一部に対してのみに対してのアノテーションに留まっています。
AIモデルの完成度を高め、性能を向上させようとしても、モデルは学習されたデータの質に完全に依存してしまうことから、データは実行すべきタスクに応じて最高の品質と関連性を持つものでなければなりません。
そのために適切なデータセットの選択、またそれらのデータへの効率良いラベル付けを行うことが不可欠となります。
また、機械学習モデルを可能な限り高性能なものにするためには、トレーニングセットがさまざまなシナリオを代表するものでなければならず、データ選択のプロセス段階で、モデルが十分な性能を発揮できるようなデータの選択とフィルタリング作業が欠かせません。
Lightlyの自己教師あり学習によるキュレーション技術は、冗長な類似データを除去し、モデルの精度を向上させ、更にデータラベリングのコストを大幅な削減することから、既に自動運転開発、ロボット開発、衛星画像解析等の多くの最先端のコンピュータビジョン開発等の研究開発で利用されています。
Lightlyの5つの特徴
データの理解
RAGを用いて社内データでのLLM活用を始めたものの、回答の精度が低い。ハルシネーションが多い。
RAGを用いて社内データでのLLM活用を始めたものの、回答の精度が低い。ハルシネーションが多い。
データの課題
冗長なデータは排除し、外れ値や特殊なシナリオは保持する機能により、アノテーションのコストと時間を大幅に節約できます。例えば、道路の画像のデータセットの場合は、同じ街灯で撮影された似た画像を削除する一方、道路を横断する人々等の興味深いシナリオの画像を残したり、さまざまなタイプの道路標識、車両、歩道上の状況などの異なるクラスタの画像が十分表現されていることを確認することが出来ます。
冗長なデータは排除し、外れ値や特殊なシナリオは保持する機能により、アノテーションのコストと時間を大幅に節約できます。例えば、道路の画像のデータセットの場合は、同じ街灯で撮影された似た画像を削除する一方、道路を横断する人々等の興味深いシナリオの画像を残したり、さまざまなタイプの道路標識、車両、歩道上の状況などの異なるクラスタの画像が十分表現されていることを確認することが出来ます。
効率的なデータパイプラインの構築
API(Application Programming Interface)により、既存のデータパイプラインに簡単にインテグレートができます。
API(Application Programming Interface)により、既存のデータパイプラインに簡単にインテグレートができます。
扱うデータの種類
画像やビデオ映像を扱います。このようなデータは、あらかじめ決められた構造を持たない非構造化データであり、画像やビデオのフレームの何処にでもどんな物でも現れる可能性があります。そのため解析の難易度は高く、サンプル数が多い場合には特にブラックボックス化してしまいます。このブラックボックス化を防ぐことが出来ます。
画像やビデオ映像を扱います。このようなデータは、あらかじめ決められた構造を持たない非構造化データであり、画像やビデオのフレームの何処にでもどんな物でも現れる可能性があります。そのため解析の難易度は高く、サンプル数が多い場合には特にブラックボックス化してしまいます。このブラックボックス化を防ぐことが出来ます。
データ活用の課題
エッジケース・マイニングとも呼ばれる手動の類似性検索に比べ、完全に自動化されたLightlyのプロセスは、より巨大なデータセットにも対応します。データを自動的にデータリポジトリに追加し、メタデータや多様性、或いは不確実性に基づいてデータ選択することを可能にします。
エッジケース・マイニングとも呼ばれる手動の類似性検索に比べ、完全に自動化されたLightlyのプロセスは、より巨大なデータセットにも対応します。データを自動的にデータリポジトリに追加し、メタデータや多様性、或いは不確実性に基づいてデータ選択することを可能にします。

製品についてのお問い合わせは、こちらから
活用例
自動運転車開発でのデータセット作成
医療機関での手術ビデオにおける
器具検出の改善
AI駆動のセキュリティカメラ開発
ケーススタディ–SDSC
手術ビデオでのアクティブラーニングを使用したYOLOv8器具検出改善 (3ページ/1,300文字)
よくある質問
Lightlyとは何ですか?
機械学習モデルは、それがトレーニングされたデータと同じくらい良いものにしかなりません。
最適なデータを見つけ出すには、非常に時間とコストがかかります。
Lightlyのデータキュレーションは、アクティブラーニングを大規模に行うことができ、エンベッディング、メタデータ、モデル予測などの入力を使って、ラベリングとモデル学習に使いたい最も価値のあるサブセットを選択することができます。
また、このデータキュレーショのプロセスを自動化することで、毎日何百万もの画像や何千もの動画を処理することができるようになります。
Lightlyのデータキュレーションはどのような問題を解決しますか?
ラベル付けされていない生の画像データを処理し、ラベル付けのために最も有益なサンプルを選択し、データセットの偏りを軽減します。
Lightlyは数百万の画像や数千の動画を含む大規模なデータセットにも対応します。
Lightly製品の主な特徴は何ですか?
Lightlyが開発した「自己教師あり学習」と「能動学習」の独自キュレーション技術により、重要なデータを自動的に選択することを可能にします。
その結果、社内の既存ソリューションとの連携も容易に行え、拡張にかかるコストを削減します。
強力で評価済みの選択アルゴリズムスイートを活用して、最も関連性の高いトレーニングデータを見つけることで、導入サイクルとデータラベリングコストを削減します。
Lightlyプラットフォームが必要な理由は何ですか?
生成AIモデル、特にコンピューター・ビジョンが注目されるにつれ、データの量よりも質に焦点が移って来ています。
学習用データセットの質を高めるためには、多くのエッジケース画像のアノテーションプロセスへのデータ渡しが必要です。
Lightlyのサポートするファイルタイプは何ですか?
現在のシステムは、以下のデータフォーマットのフィルタリングをサポートしています:画像とビデオデータ。
例として、BMP、GIF、JPEG、JPEG 2000、PNG、TIFF、WebPがあります。
次のリリースに向けて、テキストやオーディオなどの他のデータタイプのサポートに取り組んでいます。
現在サポートされていないデータ型の初期バージョンを試したい場合は、日本での窓口であるチャネルブリッジまでお問い合わせください。
Lightlyのキュレーションを採用することで、どのくらいモデルの品質が向上しますか?
現在のモデル品質の状況にも拠りますので一概には言えませんが、一例として、組み立てラインでのコンピュータビジョンによる自動品質検査と分析ビデオ検査システムの開発をしているLythium社のケースでは、以前のランダムな画像選択時とLightlyでのキュレーションにより画像選択時との精度の比較では、Lightlyによる選択時がランダム選択時を大幅に上回り、36%の精度向上の結果となりました。
オンプレミスまたはプライベートクラウドのソリューションが必要ですか?
オンプレミスおよびプライベートクラウドのソリューションがLightly社より提供されています。
Lightlyを評価することは可能ですか?
はい。 入力データの制限はございますが、無償評価も可能です。
詳しくはチャネルブリッジのお問い合わせフォームよりお問い合わせください。

お試し利用ができます
Lightlyをお試しいただくには、LightlyのWebサイトよりFree版(Community)からサインアップ、直ぐに無償でお試しいただくことが出来ます。
※入力データの規模には制限が有ります。
ご導入までの流れ
STEP
お問い合わせ・デモの
ご依頼
ご依頼
お客様の課題やご要望などを、お気軽にご相談ください。
STEP
体験・トライアルの
お申し込み
お申し込み
基本的な機能を確認されたいお客様は、Lightly社Webページよりお申し込み下さい。
構築・管理機能を含めた全機能の試用をご希望のお客様は、別途チャネルブリッジまでご相談下さい。
別途詳細なミーティングを調整させていただきます。
STEP
無料(または有料)
でのお試し期間
でのお試し期間
STEP
ご購入お申し込み
営業担当へお申し付けください。
STEP
ご購入
ご導入開始