

生成AIの精度向上
汎用人工知能のスタートアップ企業 Anoteでは、一般的なAIモデルではハルシネーション等により、特定ドメイン(社内、政府・自治体等の行政機関、研究機関等)活用には不十分なLLMの回答精度を、独自のFew Shot Learning技術により、高速に且つ低コストでLLMのモデル精度を改善する仕組みを提供しています。
生成AIの課題
精度・ハルシネーションの課題
RAGを用いて社内データでのLLM活用を始めたものの、回答の精度が低い。ハルシネーションが多い
データの課題
LLM用のデータクレンジングに膨大な時間とリソースがかかっている
データ活用の課題
サイロ化された社内データのうり、どのデータを使って生成AIの社内向けソリューションを活用すれば良いのか?
セキュリティの課題
社内の内部データを学習させる場合に、そのデータが外部に漏れるリスクがある
大規模言語モデル(LLM)は驚異的な能力を発揮しますが、業務で日常的に関心を抱くタスクとの間には大きなギャップが存在しています。
このギャップを埋めるため、Anote プラットフォームは生成型 AI モデルを人間中心(Human Centric)でのフィードバックと組み合わせ、一般的な AI モデルを特定のドメイン向けのユースケースに変換するための学習プロセスのアノテーションツールData Labelerと、社内の機密を守りつつ文書と対話できるAIモデルPrivete Chatbotを提供しています。
このPrivete Chatbotは、ユーザーのローカル環境で動作し、文書データは安全にローカル環境に保管されます。
ChatGPT を始めとする大規模言語モデル(LLM)技術と、検索拡張生成-RAG (Retrieval Augmented Generation)技術の組み合わせが、企業内の大規模で多様なデータに基づいた情報から多彩な業務自動化や意思決定プロセスの改革を加速しています。
その一方で、十分なプロンプトを駆使しても十分な精度の回答が得られず、またハルシネーションの課題 、 セキュリティ上の危惧等が、企業内での生成AI活用の流れを阻む大きなネックにもなっています。
Anoteでは、LLM の精度を向上させるために、
ユーザーからのフィードバックを用いて、
モデルを改善する仕組みを提供しています。

Anoteでは、LLM の精度を向上させるために、ユーザーからのフィードバックを用いて、モデルを改善する仕組みを提供しています。
ダウンロード資料 RLHF 人間のフィードバックからの強化学習
このアルゴリズムは、ロボット操作、ゲームプレイエージェント、パーソナライズされた推薦システム、自動運転車など、様々な分野でその有効性が示されています。RLHFの魅力的な事例について、この記事を是非ご一読ください。
(4ページ/3,300文字)
RLHF((Reinforcement Learning from Human Feedback-人間フィードバックからの強化学習)アルゴリズムは、Anoteの革新的な技術の核となっています。この技術は、ChatGPT等の生成AIのトレーニングプロセスを画期的に変革します。報酬モデルとエキスパートモデルを活用し、人間の洞察に基づく指導を組み込むことで、学習効率は格段に向上し、最適なポリシーへの収束をより迅速に実現します。
詳しくは、ダウンロード資料をご確認ください



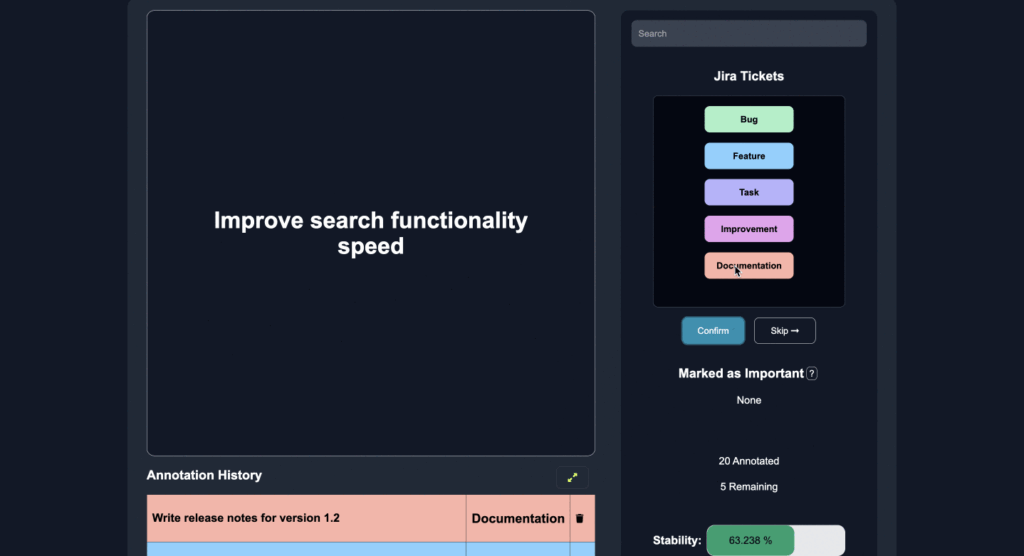
01Data Labeler
いくつかのラベル付けで、残り文書に自動でラベル付け
Anote Data Labeler は、企業が ChatGPT のような大規模言語モデルのLLM 技術を活用する際に、企業内の膨大なデータのカスタマイズと最適化、Few-Shot Learning の技術を用いた人間中心(Human Centric)のファインチューニングアプローチによるAI 駆動のラベリングプラ ットフォームです 。
この技術により、LLM でのハルシネーションを抑制し、より高い精度の企業内でのデータセット構築が実現されます。
LLMからの回答精度を高めながら、大幅な“時間、コスト、労力”の節約を可能にします。
特徴
Few-Shot Learning の技術により、ほんの数例にラベルを付けることで、残りの文書に自動的にラベル付けを行うことができます。
このテクノロジーは、Human in the loop、同期、およびコンテキスト機能と組み合わされ、テキストデータに注釈を付ける画期的な方法を提供します。
「テキスト分類」「文書ラベル付け」「感情分析」「固有表現認識」「話者ダイアリゼーション」「品詞タグ付け」等をサポートし、結果の説明可能性と、変化するビジネス要件に迅速に適応する柔軟性も提供します。
LLM のファインチューニングと、検索拡張生成 (RAG) として知られるプロセスを組み合わせることで、精度が向上した応答が生成されます。
生成AIでの、膨大な数の社内の非構造化データを活用に
- 非構造化データ(PDF、TXTなど)や構造化データ(CSVなど)のアップロード、外部データソースとの統合を可能にします
- 従来の手作業でのデータラベリングの面倒さ、時間の掛かり過ぎ、高コストという問題を解決します
- LLMモデルのファインチューニング
- 人間中心のAIアプローチとFew-Shot Learningによる、強力データラベル付けプラットフォーム
Data Labelerの主な機能
Few Shot Learning
少数の例を用いた学習で、データアノテーションを効率的に行います。
少数の例を用いた学習で、データアノテーションを効率的に行います。
Human-Centered AI
人間中心のAIアプローチを採用し、時間と共にAIモデルを改善します。
人間中心のAIアプローチを採用し、時間と共にAIモデルを改善します。
Fine-Tuning LLMs
ユーザーデータを使用してAIモデルをカスタマイズします。
ユーザーデータを使用してAIモデルをカスタマイズします。
Sentiment Analysis
テキスト内の感情を分析します。
テキスト内の感情を分析します。
Sentiment Analysis
テキスト内の感情を分析します。
テキスト内の感情を分析します。
Named Entity Recognition
テキスト内のエンティティを識別し分類します。
テキスト内のエンティティを識別し分類します。
Summarization
長いテキストを簡潔な要約に凝縮します。
長いテキストを簡潔な要約に凝縮します。
Private Chatbot Models
データのプライバシーとセキュリティを保ちながらGPTモデルを構築します。
データのプライバシーとセキュリティを保ちながらGPTモデルを構築します。
API Integration
モデル推論APIを提供し、ローカルでの予測を可能にします。
モデル推論APIを提供し、ローカルでの予測を可能にします。
Multi-Annotator Collaboration
複数のアノテーターによるコラボレーション活用をサポートします。
複数のアノテーターによるコラボレーション活用をサポートします。
導入ステップ
STEP
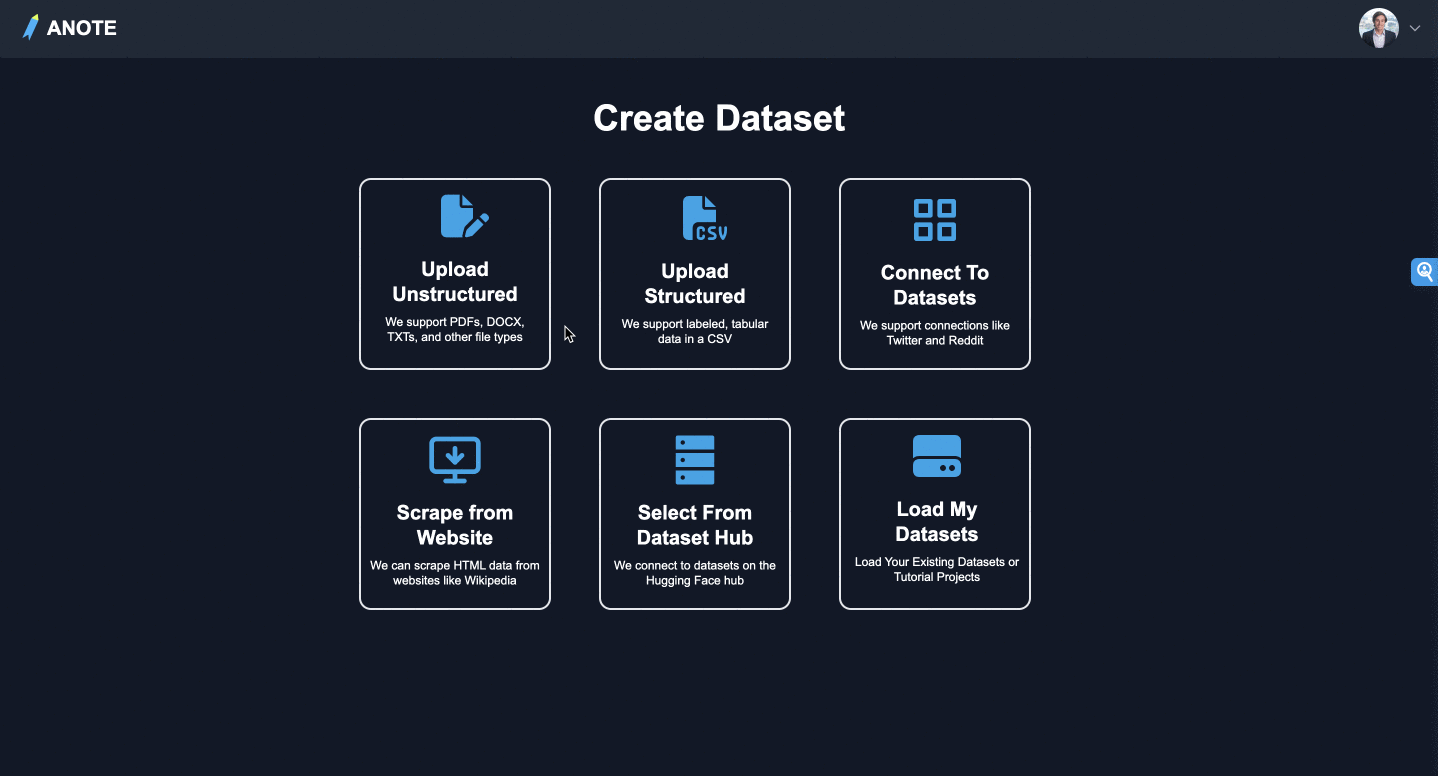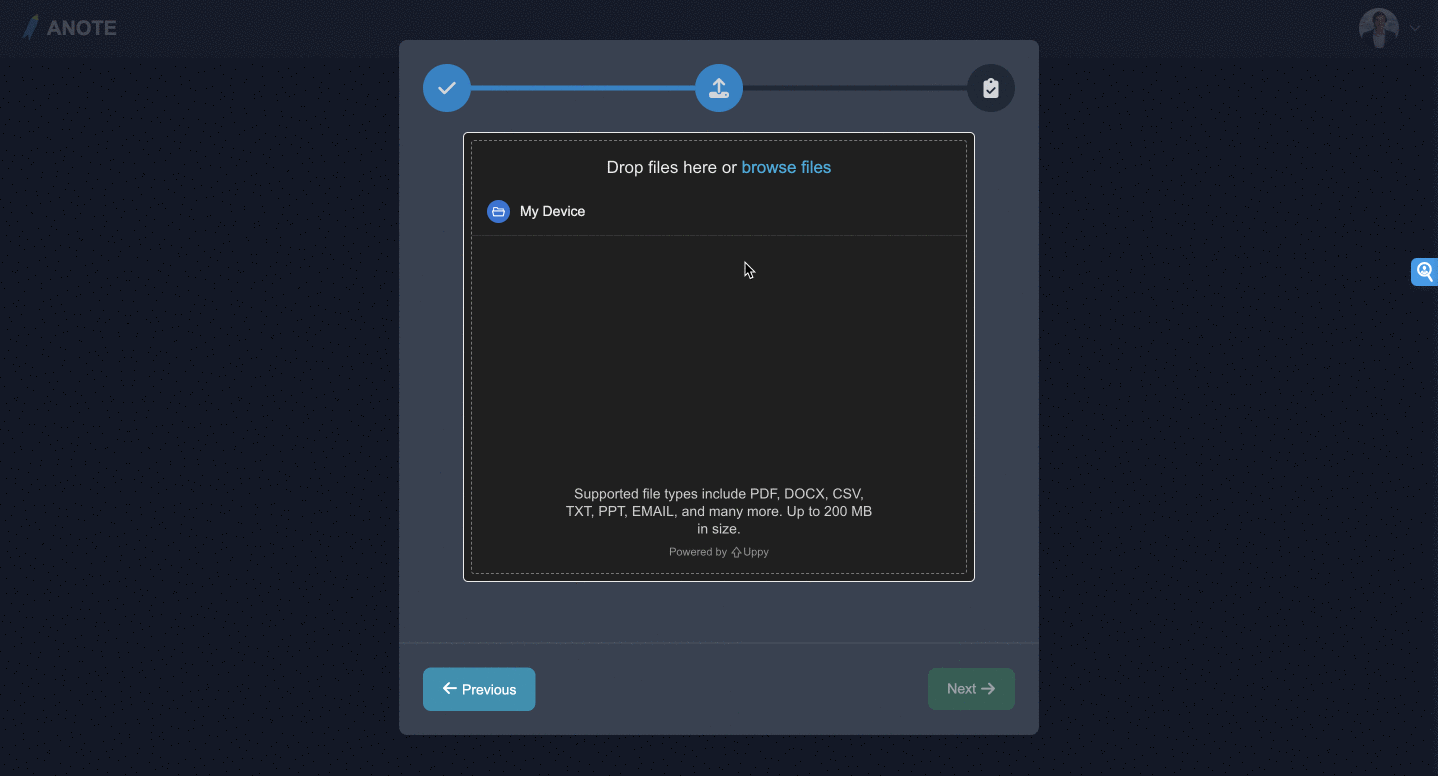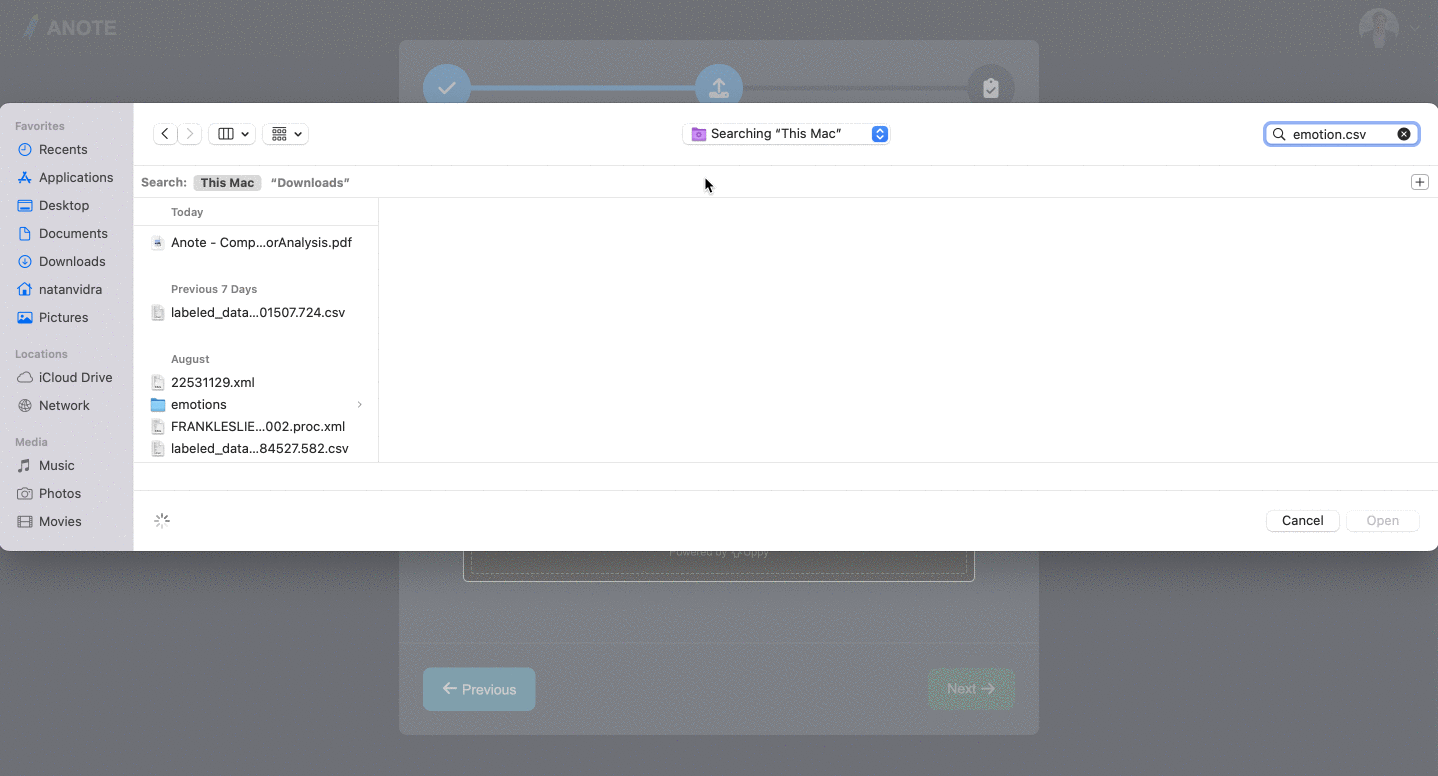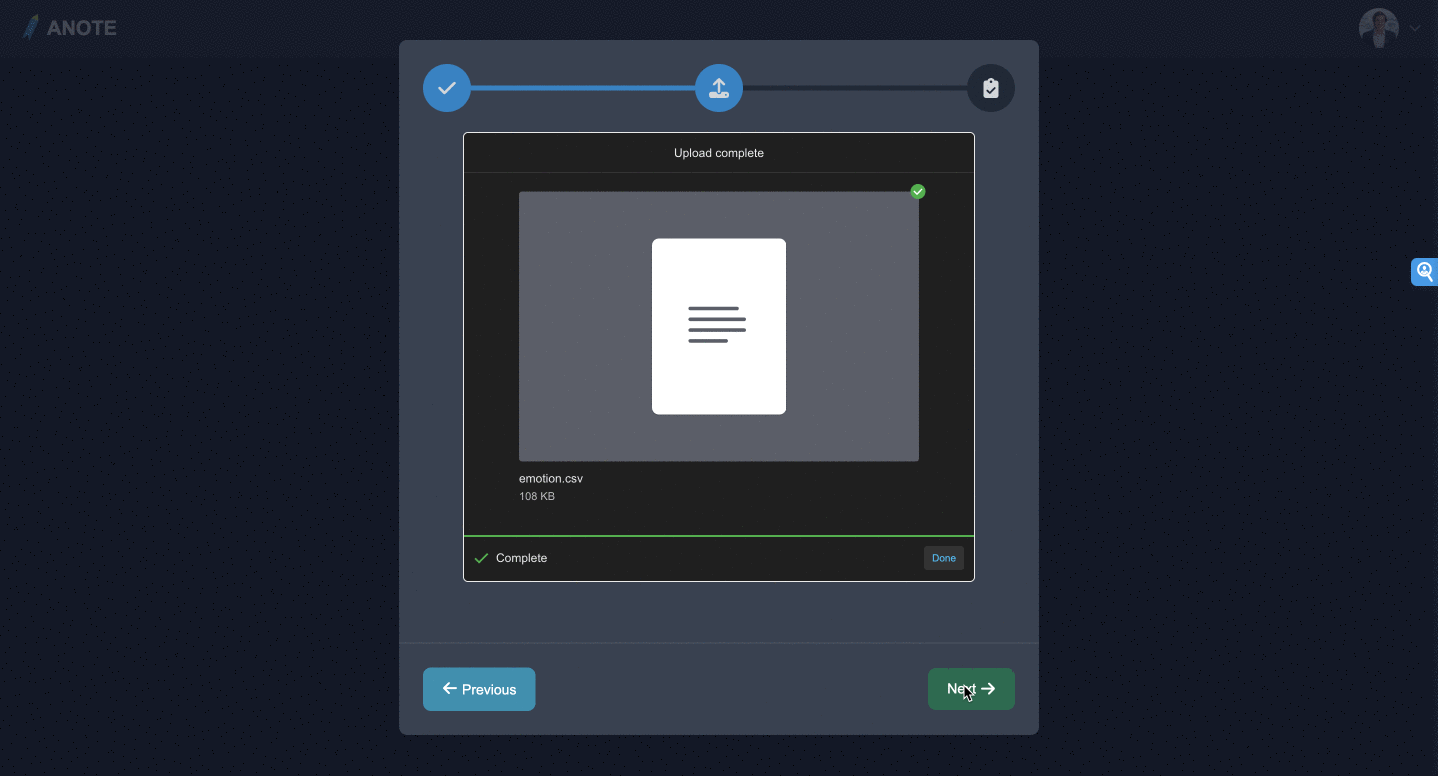
アップロード
新しいテキストベースのデータセットを作成します。データセットは以下のような経由で行う事ができます。
- 非構造化データセットのアップロード
- 構造化データセットのアップロード
- データソースへの接続
- ウェブサイトからのデータセットのスクレイピング
- Hugging Face Hubからの選択
STEP
カスタマイズ
- タスクの種類を選択
- テキスト分類、固有表現認識、質問応答
- 気になるカテゴリ、エンティティ、または質問を追加し、ラベル付け関数を挿入して専門分野を追加
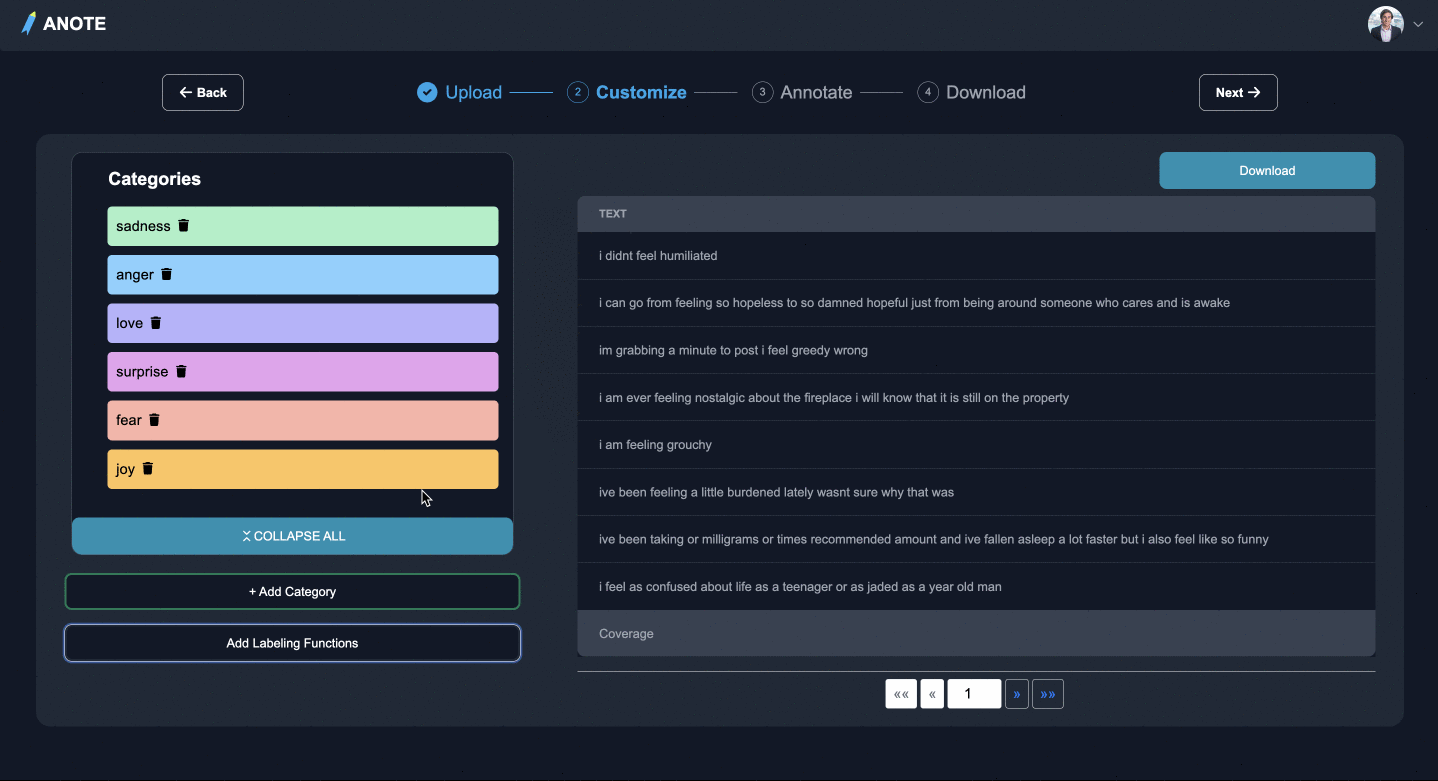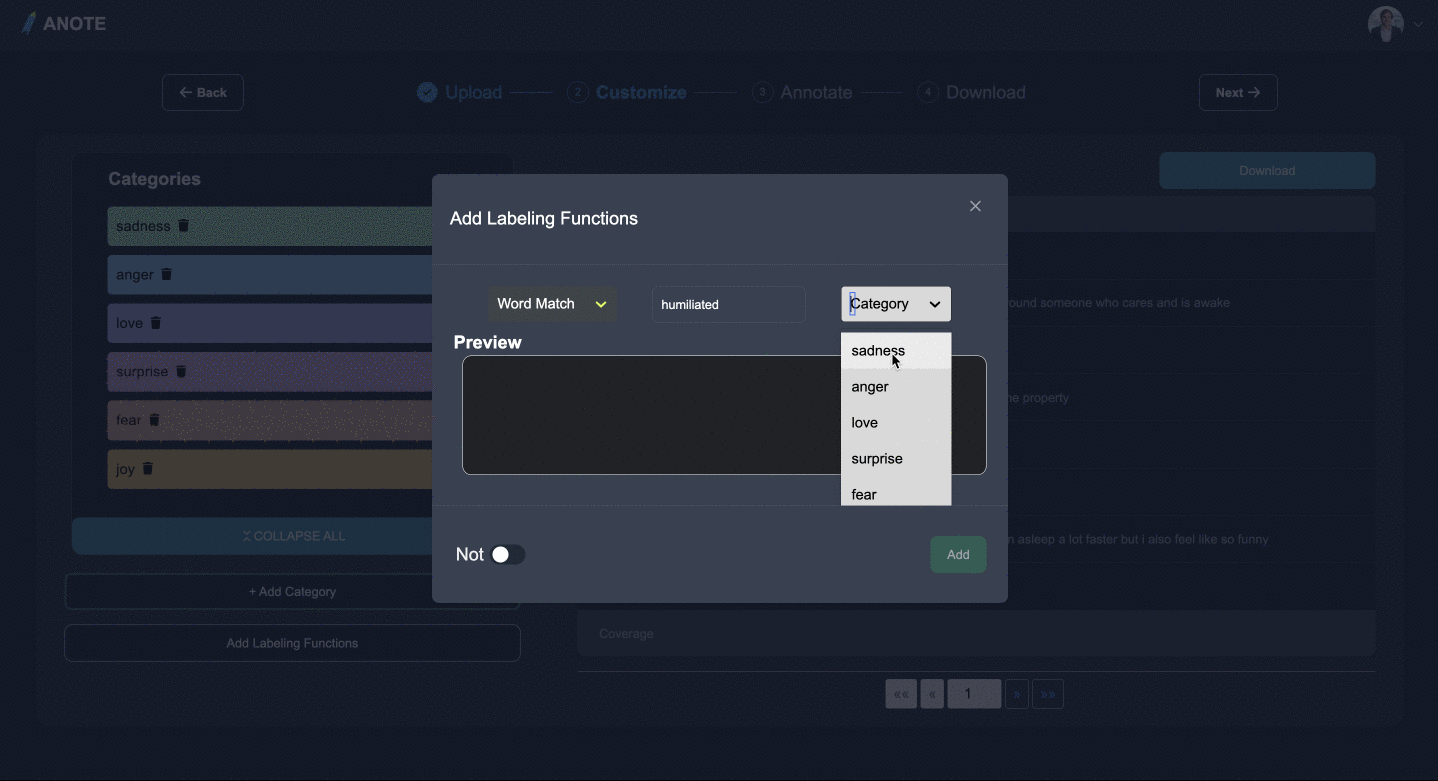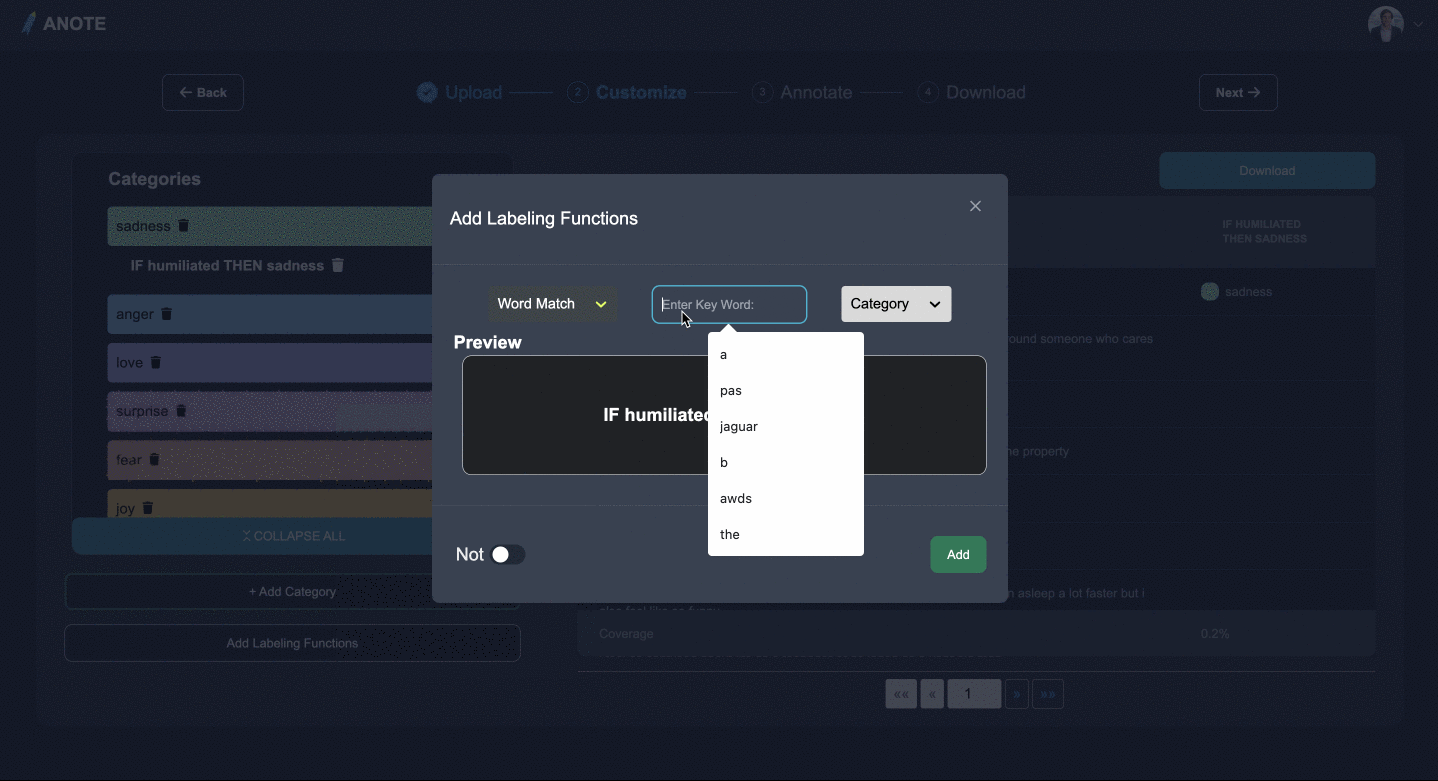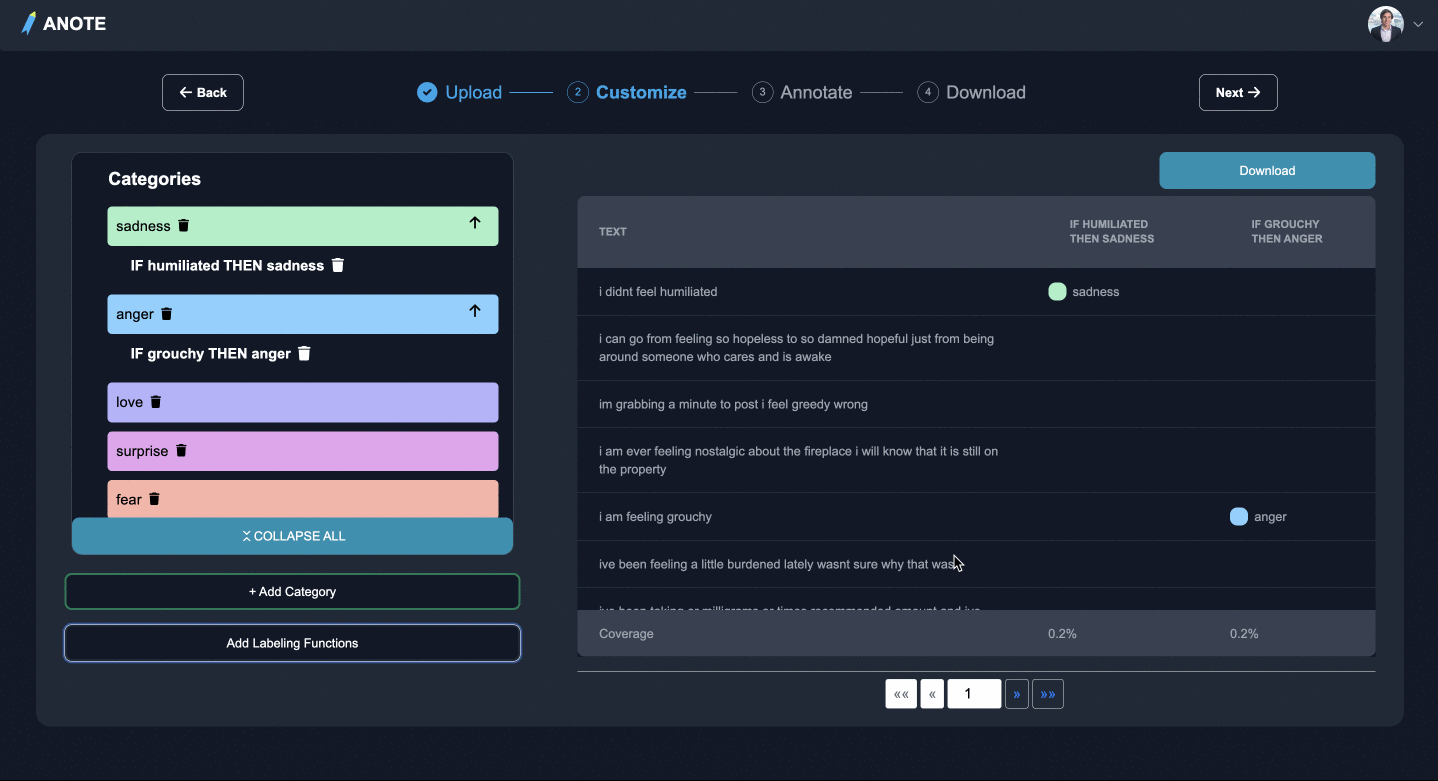
STEP
アノテーション
いくつかのカテゴリ、エンティティ、または質問への回答にラベルを付け、重要な機能にマークを付けます。
いくつかのエッジケースに注釈を付けると、モデルは人間のフィードバックから積極的に学習および改善し、残りのラベルを正確に予測します。
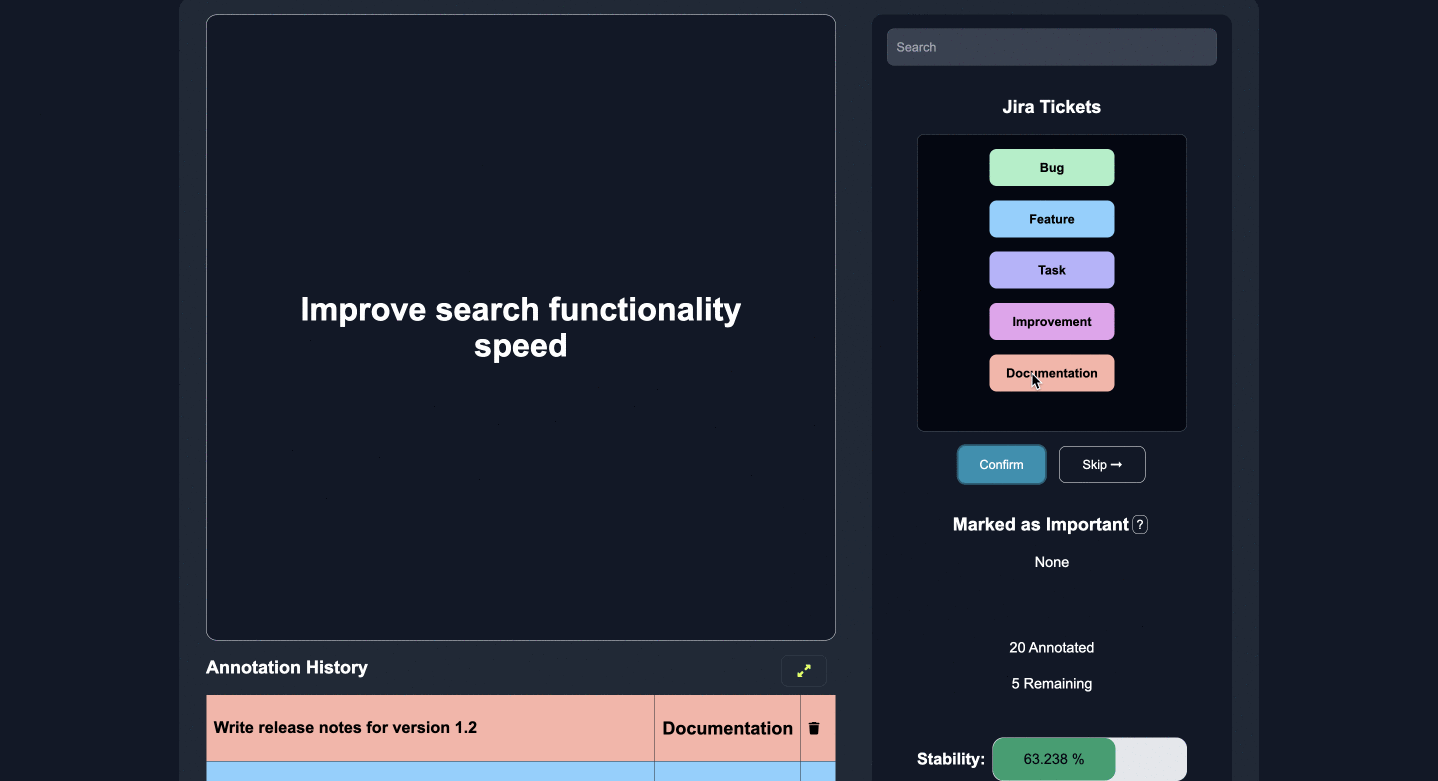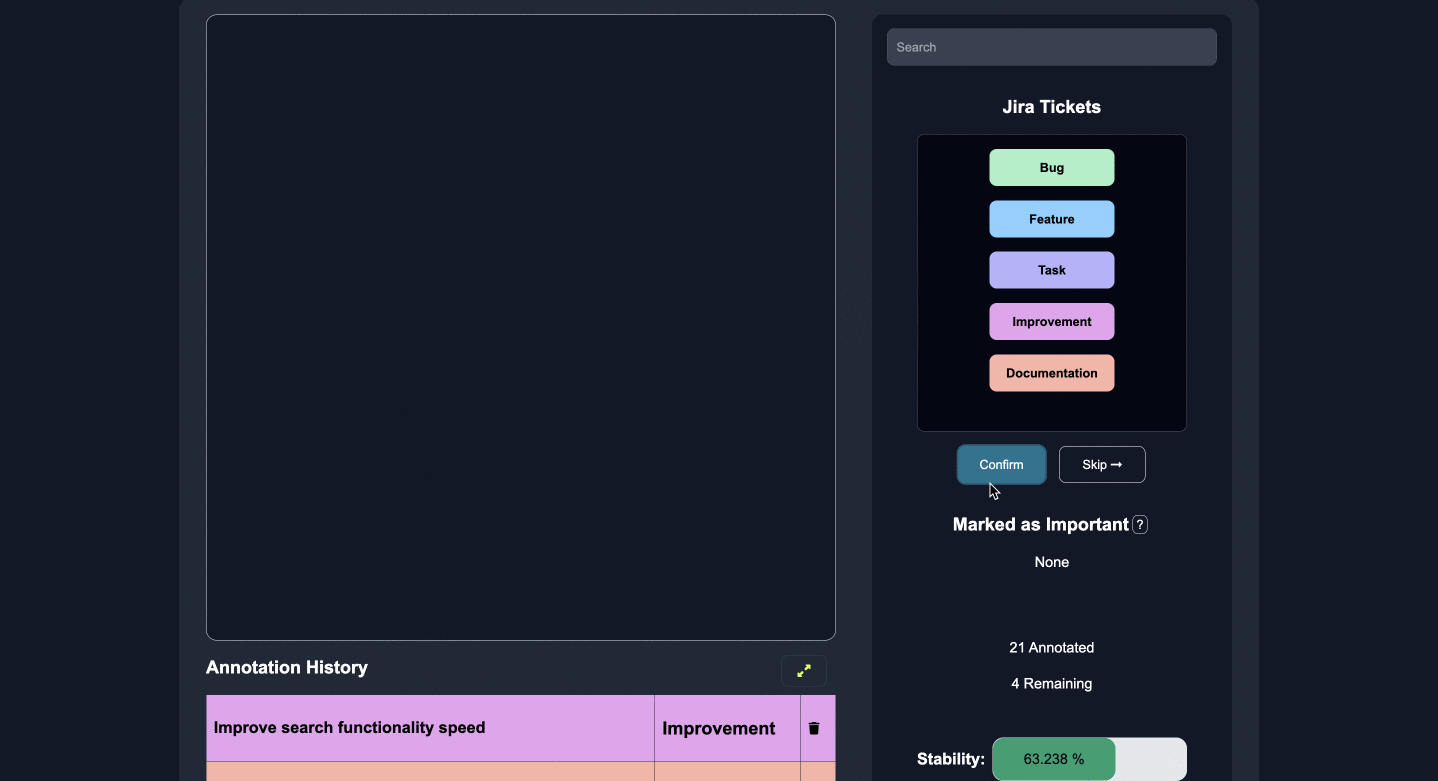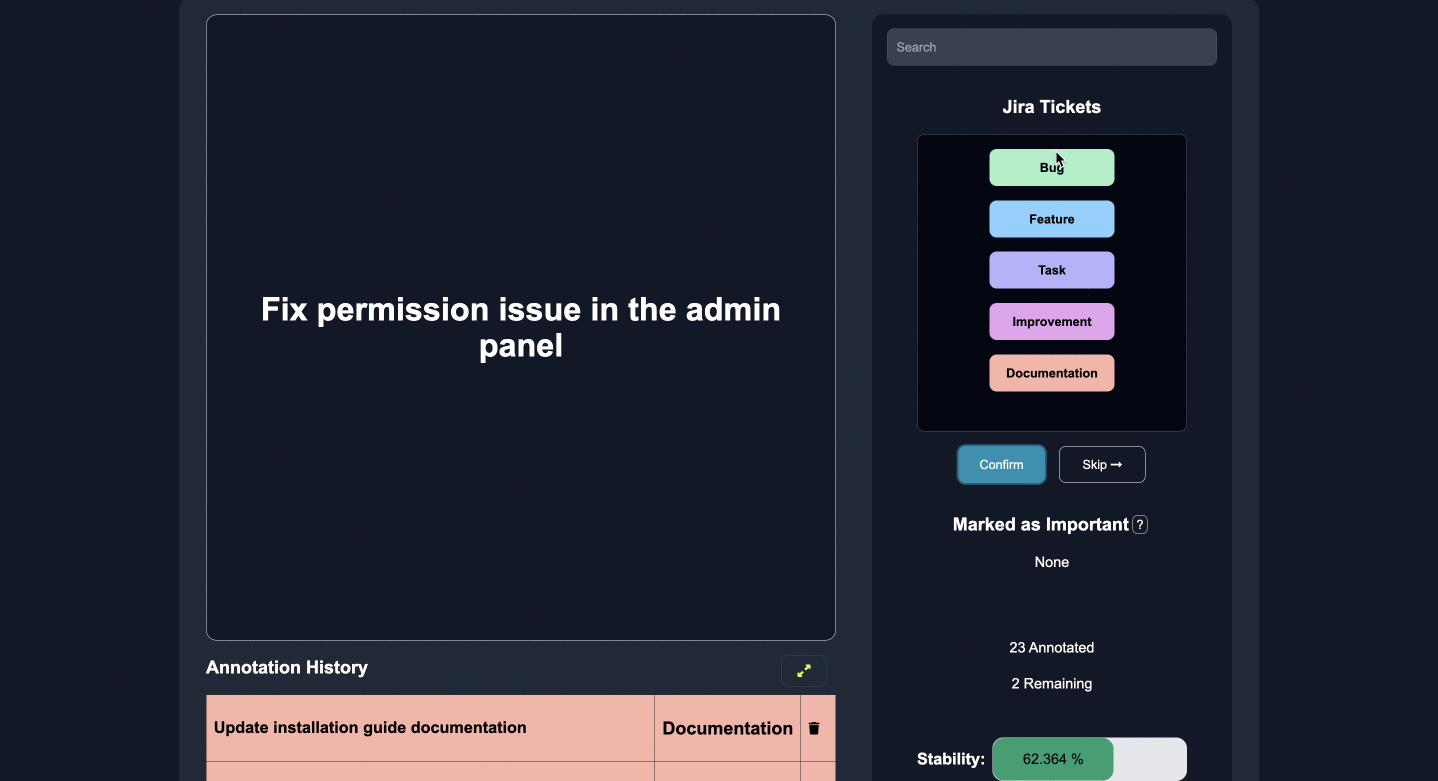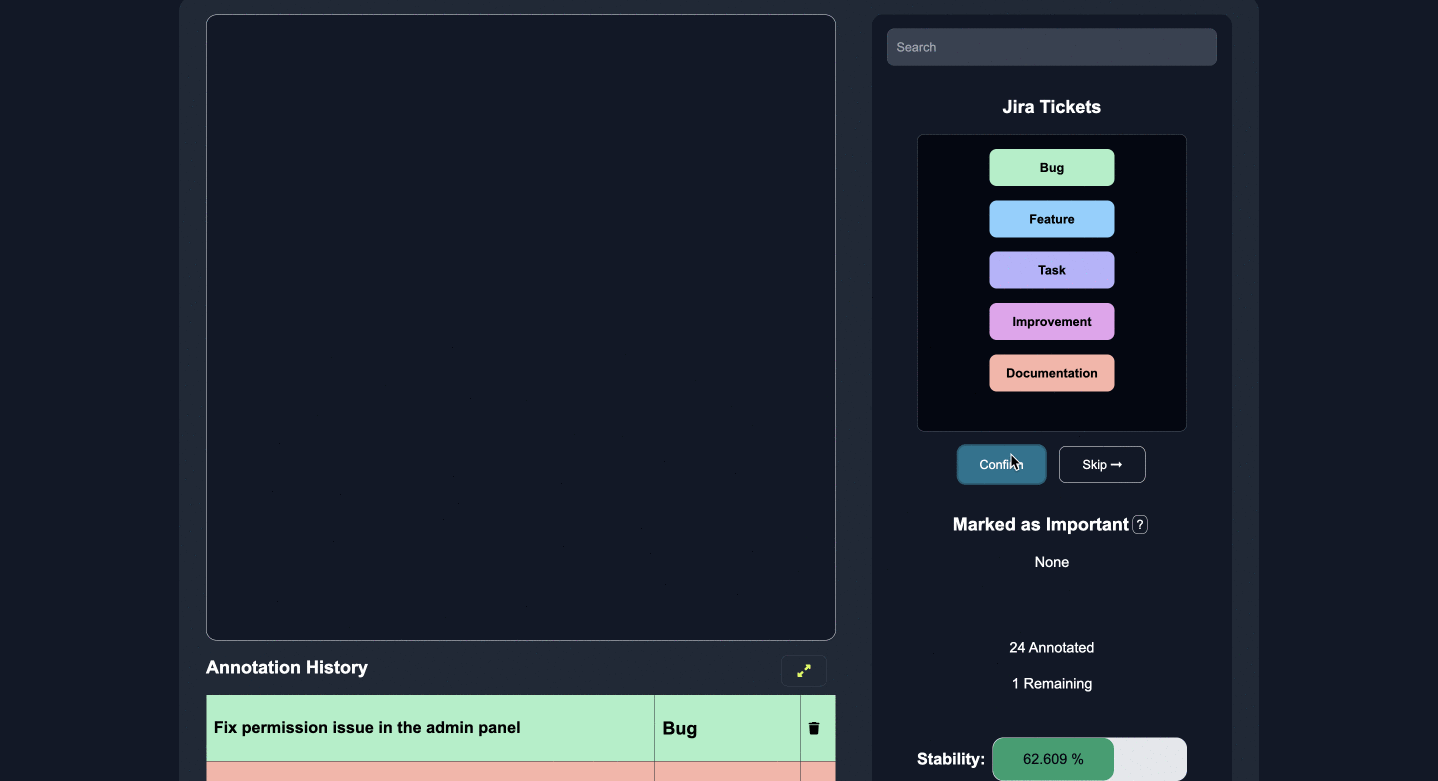
STEP
ダウンロード
ラベル付けが完了したら、結果のラベルと予測を CSV または JSON としてダウンロードします。
更新されたモデルを API エンドポイントとしてエクスポートして、将来のデータ行をリアルタイムで予測します。
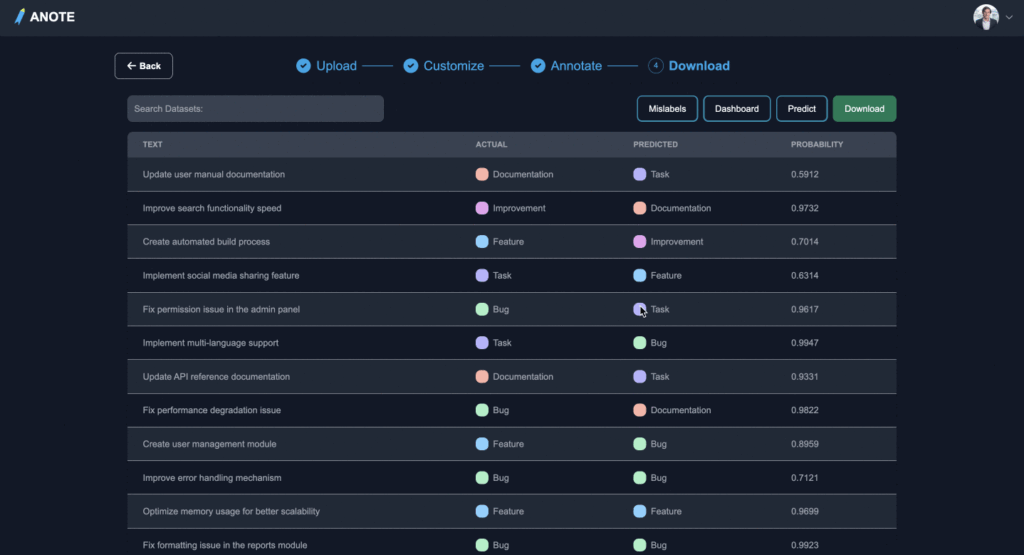
Data Labeler
02Private Chatbot
ユーザーのローカル環境で動作し、
文書データは安全に保管するLLM環境
Anote Private Chatbotは、企業内の機密性やプライバシーへの配慮が必要な文書と対話できるAIモデルです。ユーザーのローカル環境で動作し、文書データは安全に保管されます。
GPT-4ALL や LLAMA2 などのモデルを使用したプライバシー保護のLLMにより、機密性とプライバシーを守りつつ、クエリに基づいて文書を提供し、効果的な検索と文書解析に活用されます。
Private Chatbot は、ファインチューニングされたモデル ID を入力してモデルのパフォーマンスを向上させ、特定のドメインに関してより正確でカスタマイズされた回答を提供します。
モデルは尋ねたい質問に対して、固有のトレーニング データに基づいてファインチューニングされているため、より正確です。
プライバシーを保護しながら財務書類とチャットし、データを安全に保ちます。
ドキュメントをローカルサイロにアップロードします
書類について質問します。
答えを見つけてデータと対話します。
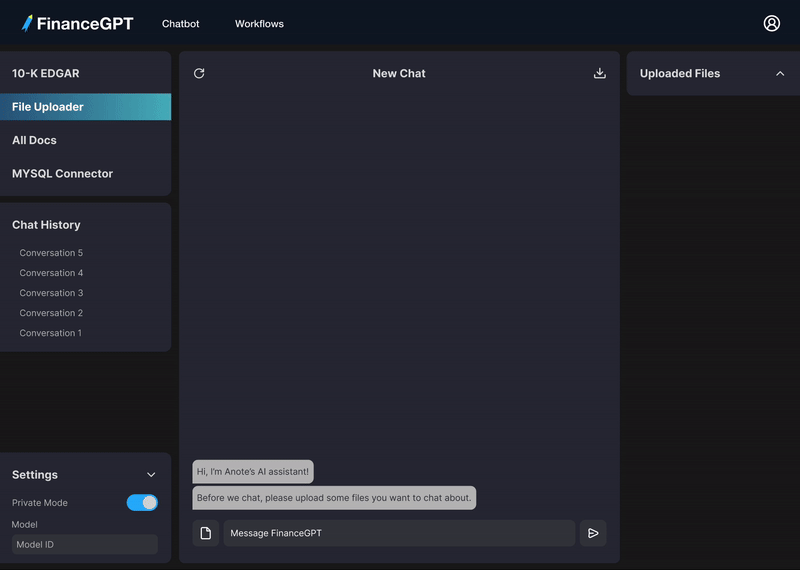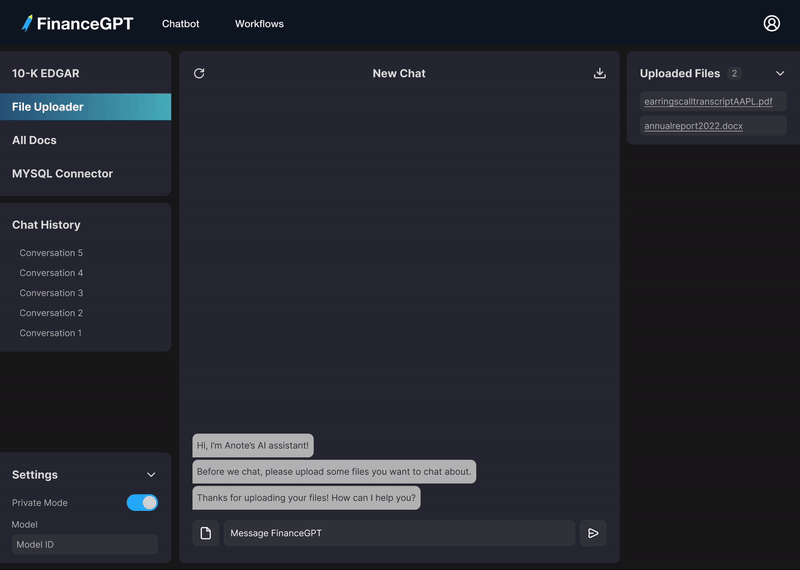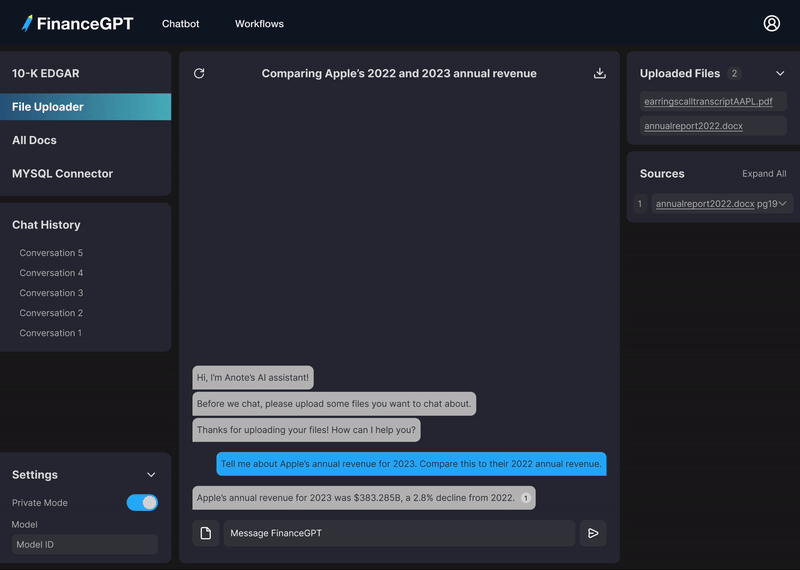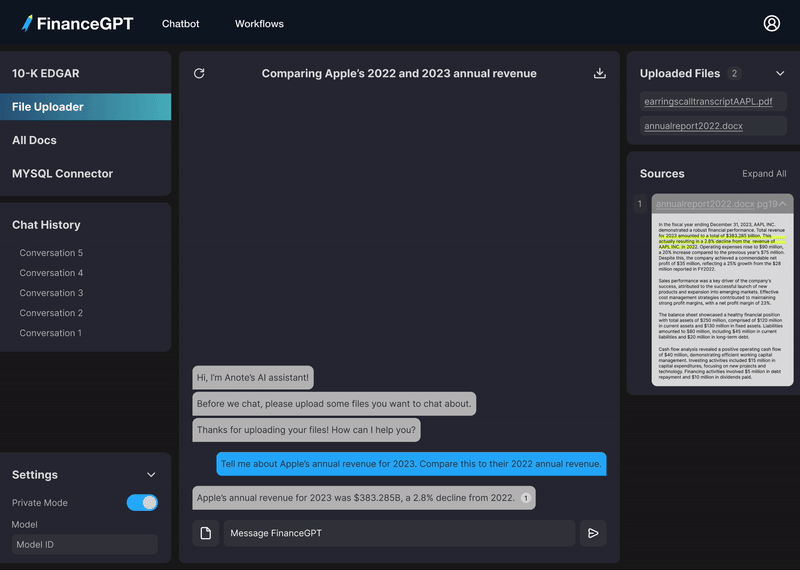
モデルの答えの出典となった特定のドキュメントとページ番号を表示します。
ハルシネーションを避けるために、モデルが答えを取得した場所から関連するテキストの部分を表示します。
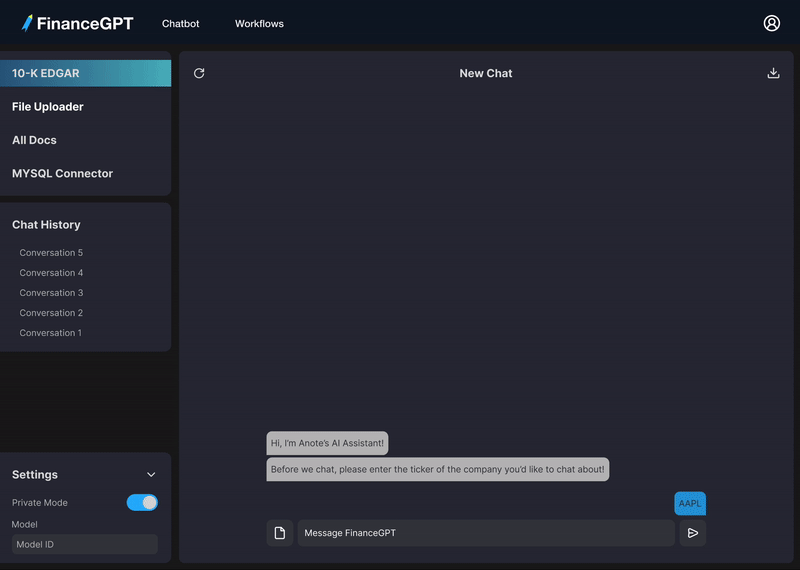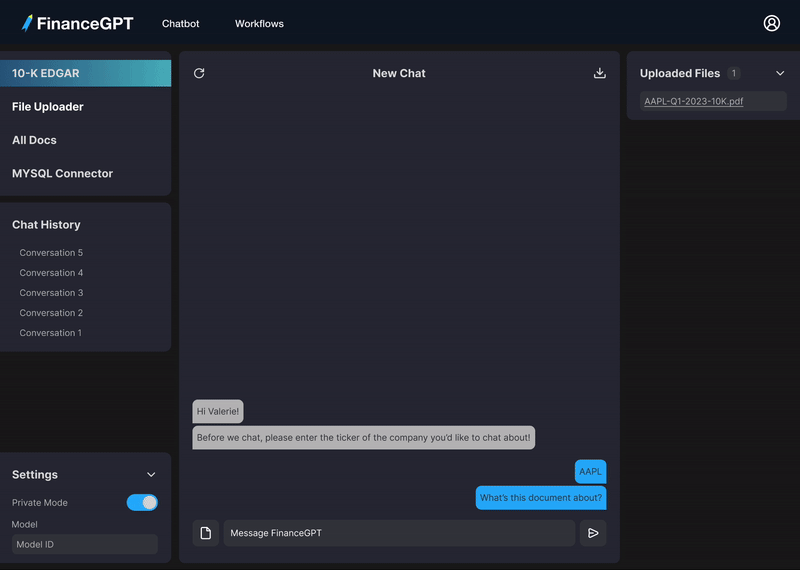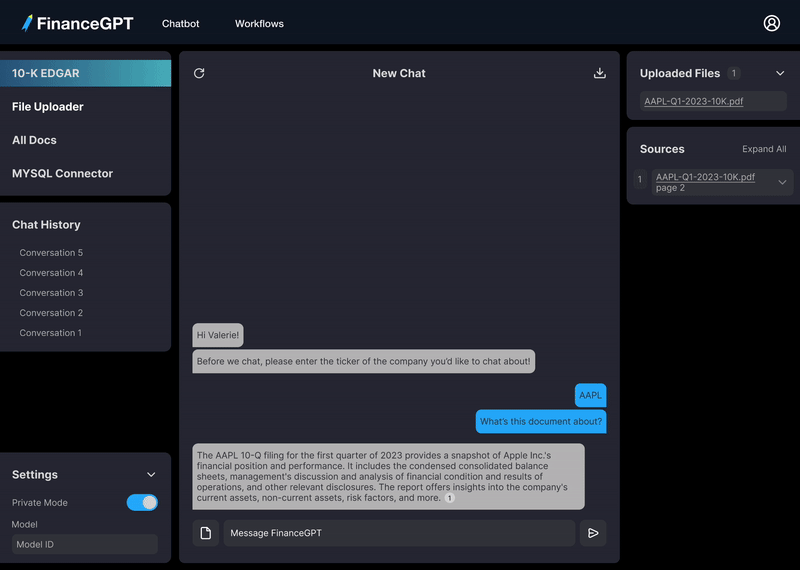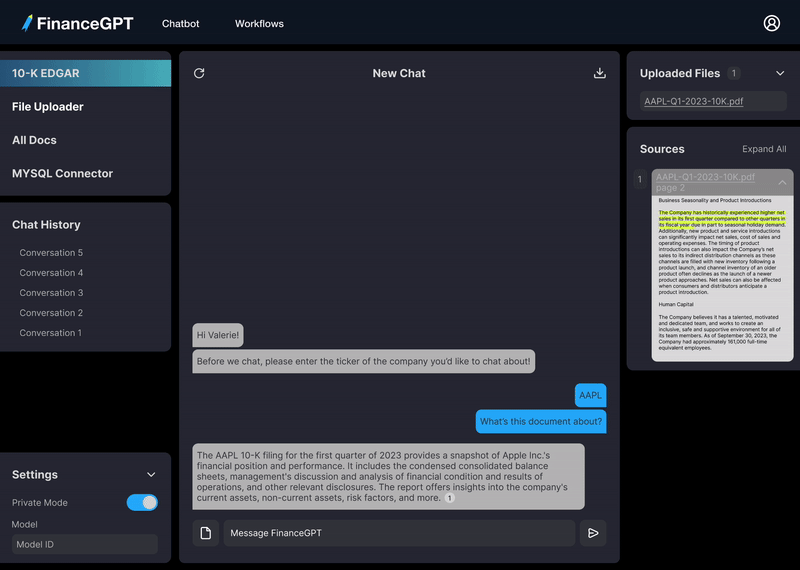
引用先・参考の文献
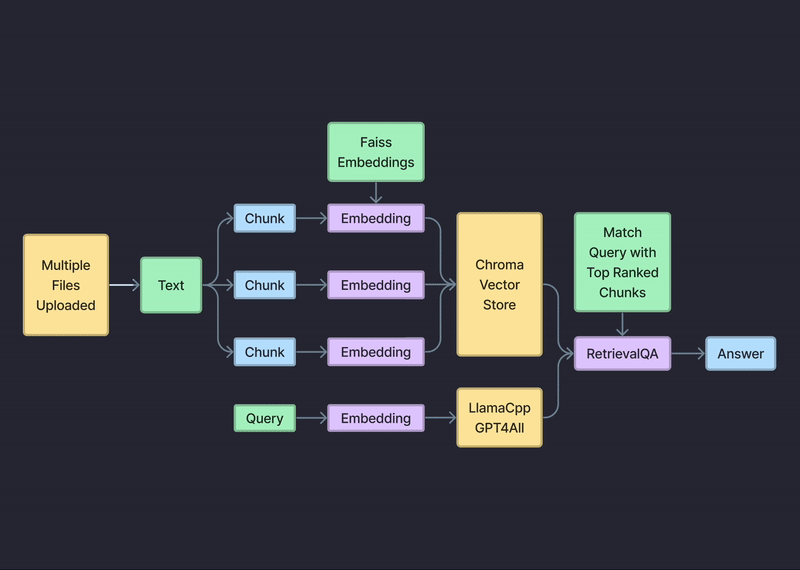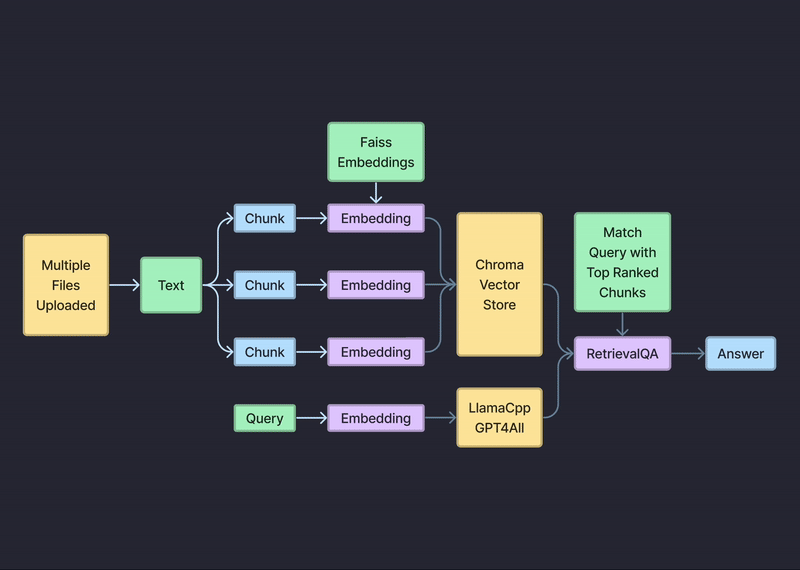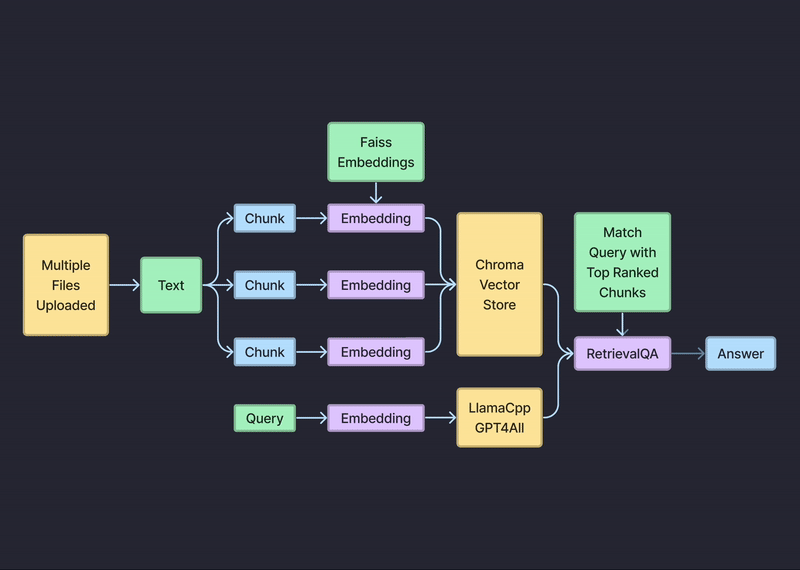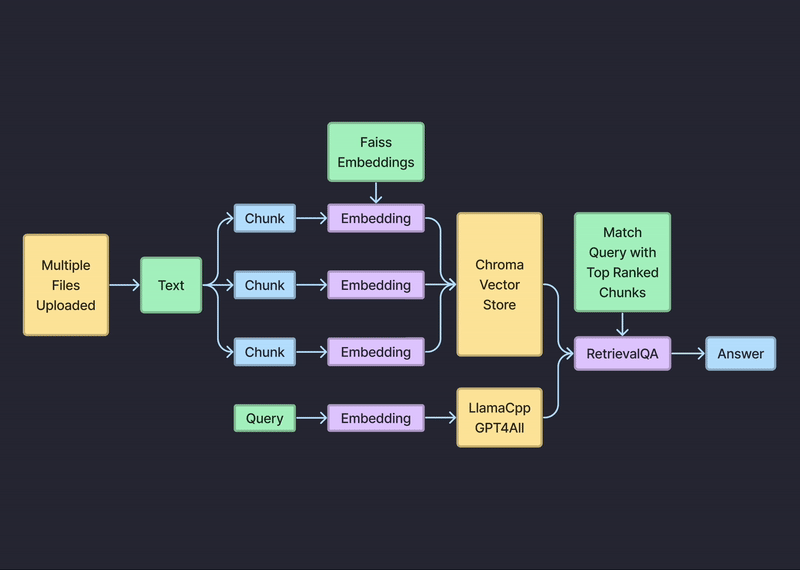
アップロードされたデータは、ローカルの mysql ベクターデータベースにローカルに保存されます。
GPT4All や Llama2 などの LLM は、デバイス上でローカルに実行されます。
すべてのクエリとドキュメントはコンピュータ上に残り、データ サイロから離れることはありません。
特徴
AnoteのPrivate Chatbotは、企業が生成的AIとプライバシーを保護するLLMを活用し、プライベートとデータを安全に保ちながら文書とチャットすることを可能にします。
Private Chatbotは、企業に独自のAIアシスタントを提供し、特定の組織の人工知能最高責任者の役割を果たします。組織のメンバーは、組織に関するあらゆる質問をすることができ、Private Chatbotは、データをローカル、オンプレミス、プライベート、セキュアに保ちながら、組織のデータに基づいてあらゆるクエリに答えることができます。
また、組織のメンバーは、関連する洞察を得るために自身の文書とチャットすることができ、企業内の文書内の具体的な答えの出所の引用が表示されます。
企業にとって、これはオンプレミスのGPT-for-your-businessとみなすことができ、企業は自社のニーズに特化した独自のGPTを持つことができます。
同時に、データはオンプレミス、ローカル、プライベート、セキュアに保管されるため、企業は機密データやプライベートデータを外部に共有するリスクがありません。

Private Chatbotの主な7つの機能
これらの機能を組み合わせ、Anote Private Chatbotは、生成AIモデルの能力を使用して、プライバシーを保護する方法でユーザーが文書とチャットできるようにします。
ローカルでの実行、ドキュメントの保存、プライバシーを意識したモデル、セキュアなインフラストラクチャー、ユーザーコントロールに重点を置くことで、データの機密性、安全性、オンプレミス性を確保します。
ローカル環境
Anote Private Chatbotは完全にユーザーのローカル環境内で動作し、文書のやりとりに安全でプライベートな空間を提供します。
Anote Private Chatbotは完全にユーザーのローカル環境内で動作し、文書のやりとりに安全でプライベートな空間を提供します。
ドキュメントの保存
ユーザーのドキュメントは、Chromaベクトルストアにローカルに保存され、ユーザーのデバイスまたはローカルストレージインフラストラクチャに安全に保存されます。
ユーザーのドキュメントは、Chromaベクトルストアにローカルに保存され、ユーザーのデバイスまたはローカルストレージインフラストラクチャに安全に保存されます。
プライバシー保護検索
Anoteは、ユーザーのクエリに基づいて関連文書を効率的に検索・取得するプライバシーを保護した検索コンポーネントを組み込んでいます。検索プロセスは、機密情報を外部サーバーに送信することなく、ローカルで行われます。
Anoteは、ユーザーのクエリに基づいて関連文書を効率的に検索・取得するプライバシーを保護した検索コンポーネントを組み込んでいます。検索プロセスは、機密情報を外部サーバーに送信することなく、ローカルで行われます。
プライバシーを考慮した言語モデル
Anoteは、LlamaCppやGPT4Allのようなプライバシーを考慮した言語モデルを採用しており、ユーザーのデバイスやローカルインフラ上でローカルに動作します。これらのモデルは、ユーザーのクエリや文書が外部サーバーに送信されることを回避することで、ユーザーのプライバシーを保護します。
Anoteは、LlamaCppやGPT4Allのようなプライバシーを考慮した言語モデルを採用しており、ユーザーのデバイスやローカルインフラ上でローカルに動作します。これらのモデルは、ユーザーのクエリや文書が外部サーバーに送信されることを回避することで、ユーザーのプライバシーを保護します。
クエリと応答のプライバシー
Anoteは、ユーザーからの問い合わせと回答が非公開であることを保証します。ユーザーのクエリはローカルで処理され、システムはユーザーの文書の基本的な内容や詳細を開示することなく、関連する回答のみを明らかにします。
Anoteは、ユーザーからの問い合わせと回答が非公開であることを保証します。ユーザーのクエリはローカルで処理され、システムはユーザーの文書の基本的な内容や詳細を開示することなく、関連する回答のみを明らかにします。
安全な実行
Anoteは、実行中のユーザーデータの完全性と機密性を保護するためのセキュリティ対策を実施しています。これには、セキュアな実行環境、機密データの暗号化、セキュアなAPIとインターフェイス、ローカルインフラを保護するためのベストプラクティスの遵守が含まれます。
Anoteは、実行中のユーザーデータの完全性と機密性を保護するためのセキュリティ対策を実施しています。これには、セキュアな実行環境、機密データの暗号化、セキュアなAPIとインターフェイス、ローカルインフラを保護するためのベストプラクティスの遵守が含まれます。
Summarization
長いテキストを簡潔な要約に凝縮します。
長いテキストを簡潔な要約に凝縮します。
ユーザーコントロールと同意
Anoteは、ユーザーの管理と同意に重点を置いています。ユーザーは、どの文書を含めるかを選択したり、クエリーを開始したり、回答を受け取ったりするなど、文書やデータを完全にコントロールすることができます。システムとのやり取りは、明示的なユーザーの同意と嗜好に基づいて行われます。
Anoteは、ユーザーの管理と同意に重点を置いています。ユーザーは、どの文書を含めるかを選択したり、クエリーを開始したり、回答を受け取ったりするなど、文書やデータを完全にコントロールすることができます。システムとのやり取りは、明示的なユーザーの同意と嗜好に基づいて行われます。
Private Chatbot
03Model Inference
~推論 API を介した LLM ファインチューニング用API~
LLMのハルシネーションの減少とモデルのファインチューニングやリプロンプトに活用されます。
Anote API
API を介してプログラムでファインチューニングされたモデルと対話し、データを正確に予測します。
これらのアンサンブル モデルは人間中心(Human Centric)で、人間のフィードバックから積極的に学習して、PEFT や QLORA などのファインチューニングテクニックを組み込んでモデルのパフォーマンスを向上させます。
質問応答のベンチマーク例
金融分野の質問に対する、より正確で金融分野特有の信頼性の高い回答を返します。
ベンチマーク対象モデル: GPT-4、Claude、GPT4All、Llama2
ベンチマークされたデータセット: FinanceBench、Rag Instruct
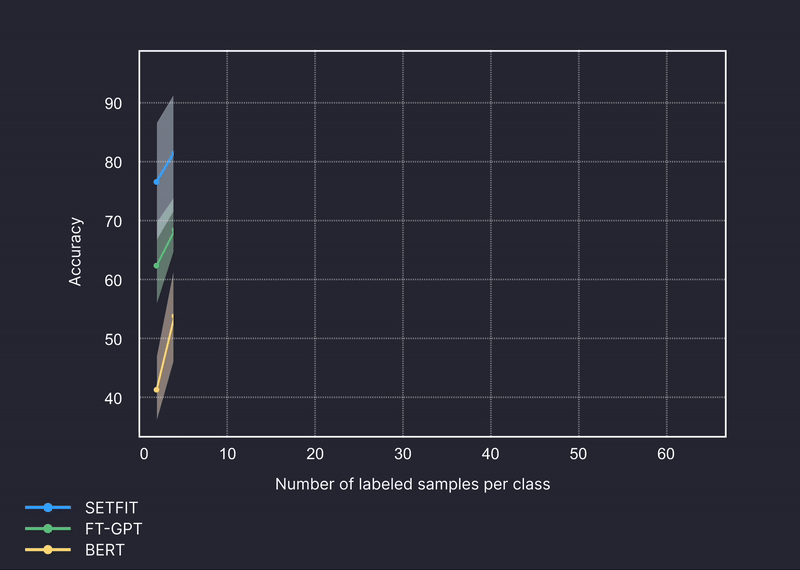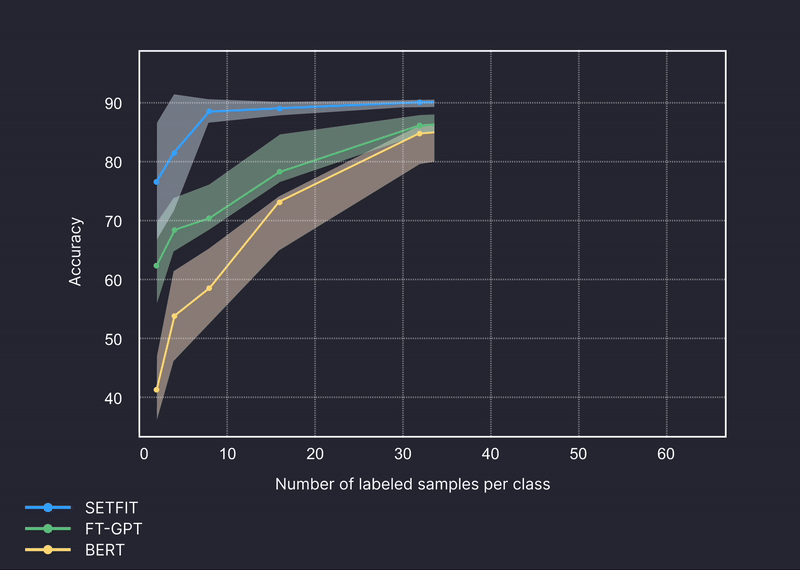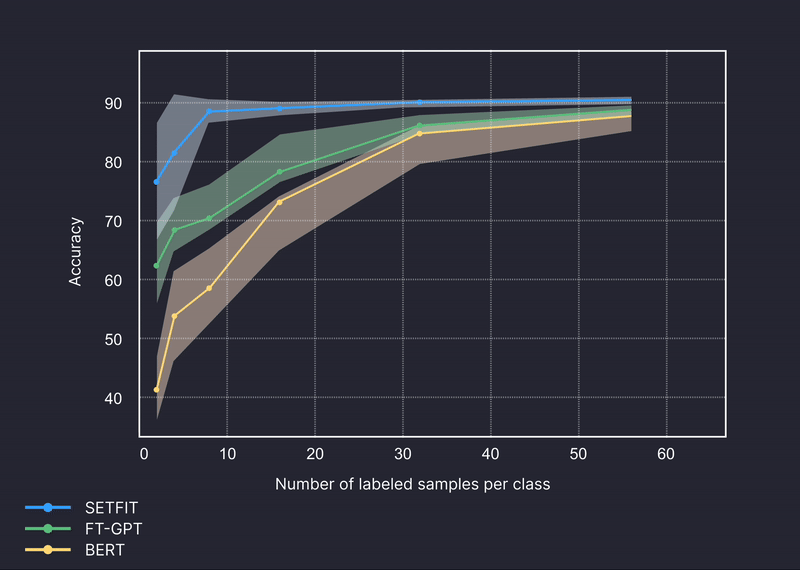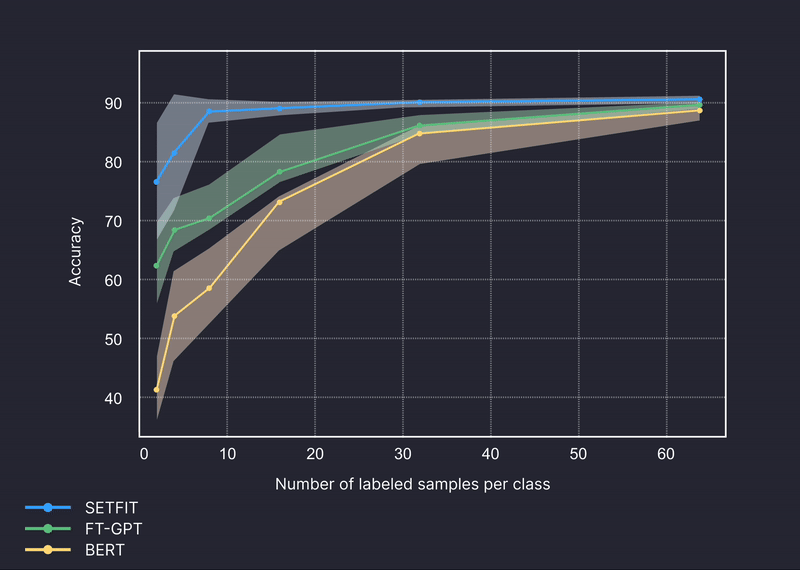
テキスト分類のベンチマーク例
より正確で、信頼性の高いドメイン固有のカテゴリ予測を行います。
ベンチマーク対象モデル: GPT-4、Setfit、BERT
ベンチマークされたデータセット: Amazon Reviews、Craigslist、Trec、金融、銀行
Model Inference
活用例
企業内での財務データ分析
医療機関での大規模な
医学データの処理と分析
競合企業の予測と分析
米国証券取引委員会 (SEC)に提出された年次報告書(10-K )分析でのAnoteの活用 (16ページ/11,000文字)
ケーススタディ Anoteインターフェースによる医療文書の要約
(4ページ/2,500文字)
よくある質問
Anoteとは何ですか?
非構造化テキスト データのラベル付けプロセスを高速化する、Few-shot Learning技術を用いたAI 支援の強力データ ラベル付けプラットフォームです。
Anoteでは最小量のラベル付きサンプルでデータにラベル付けを行います。
Anoteプラットフォームはどのような問題を解決しますか?
生成AIモデルは信頼性の低さやハルシネーション(Hallucination)と言った、AIが事実に基づかない情報を生成し、まるで幻覚を見ているかのように振る舞う現象の問題を抱えており、特にドメイン固有のユースケースに対応することが難しいという課題が有ります。
Anoteは、この限界を超え、高品質な結果をもたらすために、独自データセットでの言語モデルのファインチューニングを可能にします。時間とコストを大幅に削減し、精度を高めることで、企業が抱えるAIプロジェクトの課題に対応します。
手作業によるデータアノテーションプロセスの問題点は何ですか?
従来の手作業によるデータアノテーションによるデータラベリングは、時間が掛かり、コストがかさみ、また精度も不確実です。
企業は数ヶ月から数年の時間、高額のコストを掛けても、データにラベルエラーが存在し、最適な結果を得られないことも少なく有りません。
Anote製品の主な特徴は何ですか?
Anoteプラットフォームは、非構造化データ(PDF、TXTなど)や構造化データ(CSVなど)のアップロード、外部データソースとの統合を可能にします。
少量のラベル付けから学習し、リアルタイムで改善されたモデルを提供します。カスタマイズ可能で、直感的なGUIを通じて、効率的にデータをアノテートすることができます。
Anoteは現状とどう違いますか?
Anoteは、従来の手作業でのデータラベリングの面倒さ、時間のかかりすぎ、高コストという問題を解決します。
リアルタイムでのラベル付け、数ショットラーニング、Human In The Loopアプローチを採用しています。これにより、ユーザーは迅速に、かつ低コストでデータラベリングを実施でき、ビジネスニーズに応じてモデルを微調整することができます。
Anoteプラットフォームが必要な理由は何ですか?
Anoteは、複雑な質問、分類、エンティティの抽出など、特定のドメイン固有のタスクに対応するために必要な機能を備えています。
既存の汎用モデルや独自モデルの限界を超え、ユーザーが特定のデータセットとユースケースに最適なAIモデルを構築できるよう支援します。
これにより、モデルの信頼性が向上し、よりドメイン固有のAIタスクを効果的に実行できるようになります。
AnoteのData Labelerサポートするファイルタイプは何ですか?
Anoteは、テキスト データのみに焦点を当てており、サポートするファイルタイプには、PDF、TXT、DOCX、PPTX、HTML、電子メール、CSV、XLSX、およびその他の一般的にサポートされているテキストファイルが含まれます。
特定の種類のドキュメント (たとえば 10-K) を処理したい場合は、ドキュメント固有の分解も可能です。
AnoteのData LabelerでアノテーションしてダウンロードしたデータをPrivate Chatbotにアップロードすると、アノテーションする前のデータをアップロードした場合より、的確な回答が得られますか?
Private Chatbot の仕組みは、ファインチューニングされたモデル ID をPrivate Chatbotに入力してモデルのパフォーマンスを向上させることです。
つまり、ChatGPT だけでなく、特定のドメインに関してより正確でカスタマイズされた回答を提供します。
モデルは、尋ねたい質問に固有のトレーニング データに基づいてファインチューニングされているため、より正確です。 このファインチューニングされたモデルを Private Chatbot 製品に入力するには、いくつかの方法があります。
– FT-GPT: 公開ドキュメントの場合、GPT のファインチューニングモジュールを使用してファインチューニングされたモデルをインポートできます。
– Llama2: プライベート バージョンの場合、ファインチューニングされたモデルとして Llama2 をチャット インターフェイスに入力できます。 – Anote API: Anote のファインチューニングされたモデルをチャット インターフェイスに入力できます。
チャネルブリッジとAnoteの関係は何ですか? またAnoteを当社で取り扱うことが出来ますか?
チャネルブリッジは、Anote社の日本国内の総販売代理店です。
チャネルブリッジでは、日本国内でのAnoteビジネスチャンスを広げるご協業いただけるアライアンスパートナーを募集しています。
詳しくはinfo@ch-bridge.comまでお問い合わせください。
お試し利用ができます
Anote Data Labelerは、AnoteのWebサイトよりFree版(Basic)からサインアップをいただくことで、直ぐに無償でお試しいただくことが出来ます。
Anote Private Chatbotをお試しいただくには、弊社チャネルブリッジまでお問い合わせ下さい。
※入力データの規模には制限が有ります。
ご導入までの流れ
STEP
お問い合わせ・デモの
ご依頼
ご依頼
お客様の課題やご要望などを、お気軽にご相談ください。
STEP
体験・トライアルの
お申し込み
お申し込み
操作感を試したり、基本的な機能を確認されたいお客様は、「体験・トライアル」をお申し込み下さい。
構築・管理機能を含めた全機能の試用をご希望のお客様は、別途チャネルブリッジまでご相談下さい。
STEP
無料(または有料)
でのお試し期間
でのお試し期間
Web上で公開されている英語での電子マニュアル以外にも、別途チャネルブリッジでは日本語のマニュアルを準備中です。また技術的な個別のご質問も承りますので、お気軽にお問い合わせください。
STEP
ご購入お申し込み
営業担当へお申し付けください。
STEP
ご導入
ご導入後は開発元との連携を含めた、チャネルブリッジ技術担当によるサポートをご利用ください。
Anote についてのお問い合わせは、こちらから